
Model Fingerprint
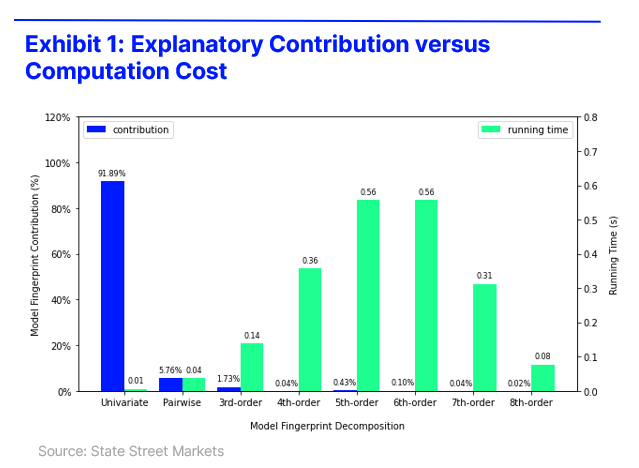
In this paper, we propose a novel model interpretability framework named Model Fingerprint. It is a bottom‑up approach to explaining machine learning models that shifts the focus from assigning feature importance to uncovering the logical structure that drives predictions. While attribution methods such as SHAP faithfully quantify how important each feature is, importance alone is a limited set of lens – much like trying to understand a movie by listing how significant each character is without considering their interactions, pivotal moments, or how the plot unfolds. Model Fingerprint identifies sets of interacting components that make a model’s behavior intelligible and produces low‑order approximations that are compact, coherent, and extensible. Fully consistent with SHAP in the limit, it reframes interpretability by connecting attribution to logic, approximation to insight, and convergence to rigor.


