By Megan Czasonis, Mark Kritzman and David Turkington
We show how our method of relevance-based prediction implements similar logic to a highly complex machine learning model, but relevance is extremely transparent.
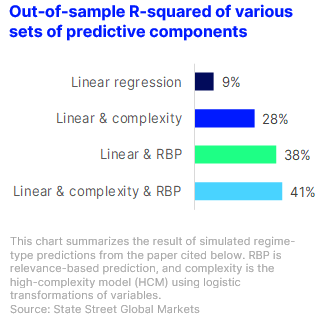
What is the best way to form predictions from a data sample? This is a big question, but at its core lies a fundamental tension between explaining the past and anticipating the future. Predictions can fail by paying too little attention to the past (underfitting) or by paying too much attention (overfitting). High-complexity machine learning models address this problem by recombining past information in thousands (or millions) of exotic ways to map out generalized rules for any situation. An alternative method, called relevance-based prediction, considers each situation one at a time, and extracts the past data that is most useful for that task. We show that there is a deep connection between the two approaches, but only relevance maintains the transparency that makes it easy to explain precisely how each past experience informs a prediction.